Working in News Tech: MH17, an impressive day to remember
When dealing with traffic of a news site like NU.nl, one quickly learns to expect the unexpected: You know there will be traffic surges, but you can not predict when they will be.
This is quite unlike, for example, ecommerce where the holiday season can be predicted. Or big event ticket sales, where the moment tickets will start to sell, is known beforehand. With breaking news, however, the moment is sudden, and the traffic surge typically is in the ballpark of ‘times 4, within 4 minutes’.
At July 17th, 2014, in the afternoon, I was heading to the train station, when on our HipChat channels there were messages about a missing airplane. That set in motion an evening of observing our various systems.
A brief history of all-hands-on-deck situations
Before, but also after July 2014, we had experience with the occasional incident troubleshooting sessions, which sometimes ran into the late hours. Some of the most memorable include:
Meltdown
An afternoon where one after another 3 of our 4 webservers started to suffer from CPU exhaustion, to the point where they weren’t able to keep up with the queue of rendering news pages. So for a couple of hours we were limping, fingers crossed, on the single remaining webserver that provided our 4 Varnish cache servers. Miraculously the problems disappeared, but we weren’t able to determine the root cause. Luckily it was a one-off.
Cache miss
Launching a complete rebuild and discovering that the performace test done by a third party, had thoroughly tested Varnish, but not the actual web site in ‘cache miss’ scenario. We already knew Varnish is great. We learned in a painful way to take more control when involving third parties.
DDoS
Site being DDoS-ed. This might have been around 2014 as well. CDNs weren’t as prevalent back then, so Varnish and HAproxy where the internet-facing components. Our manager back then did the best thing he could do: Handle stakeholder-communications and fetch dinner Döner, while a colleague and I were digging through various metrics. Turned out we were attacked by a SYN flood.
After some rather fruitless mitigation attempts, we ultimately had our datacenter configure the NetScaler1 firewall with a geo-block, targeting Asia and South America, the origins of our malformed traffic.
Blocking a couple of continents was not decided lightly, but considering being a Dutch news site, it was deemed acceptable for a brief period. The digital vandals got bored, disappeared, and the next day we lifted the geo-block.
And, as these things go, a CDN with DDoS mitigation capabilities got prioritized.
A sunny afternoon
Besides things breaking down in various ways, normal, legitimate traffic can cause quite some impact as well. And that day in 2014 might have been one of the busiest days in NU.nl history.
Breaking News
I remember it was a bright, sunny afternoon, and I just left the Sanoma office in Hoofddorp. Heading to the train station, someone mentioned on HipChat that a plane had gone missing above Ukraine. I’m not sure if it was in an editor channel, or one of our team members, giving us a heads-up of a possible breaking news push coming up.
Either way, I checked the Flightradar link to the missing airplane and I can remember noticing the altitude graph showed no descend, but just ‘stopped’. Worried, but hoping it would turn out to be just a transponder failure, I knew editors were busy trying to get information and confirmation from authorities and sources such as ANP.
Unsurprisingly, while still commuting, a breaking news push message appeared on my NU.nl mobile app:
17:13 - Passenger aircraft, flying from Amsterdam, crashed over Ukraine
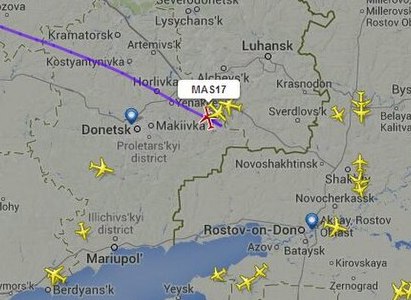
Flight path of MH17. Source: Flightradar24/wikimedia.org.
Dealing with high-volume traffic
Anatomy of a push message
Let’s see what happens when a ‘breaking news’ push is sent out:
- Editors mark a news article as ‘breaking’ and publish it.
- This triggers our ‘push notification service’, containing basic details like title and article id.
- The push notification service has a list of subscribed device ids and invokes the push APIs of Google and Apple.
- Within a couple of minutes, millions of Android and iOS devices receive the NU.nl push message.
- A certain percentage of users, more or less immediately opens the article. This results in traffic to our web-facing systems.
- This percentage depends greatly on the nature of the news and the time of day. At the end of afternoons, traffic is normally already high. This news had a high ‘open rate’2.
- After the initial burst of traffic, traffic volume ebbs down but remains high for a certain period. Also, people find their way to the desktop website where traffic will go up.
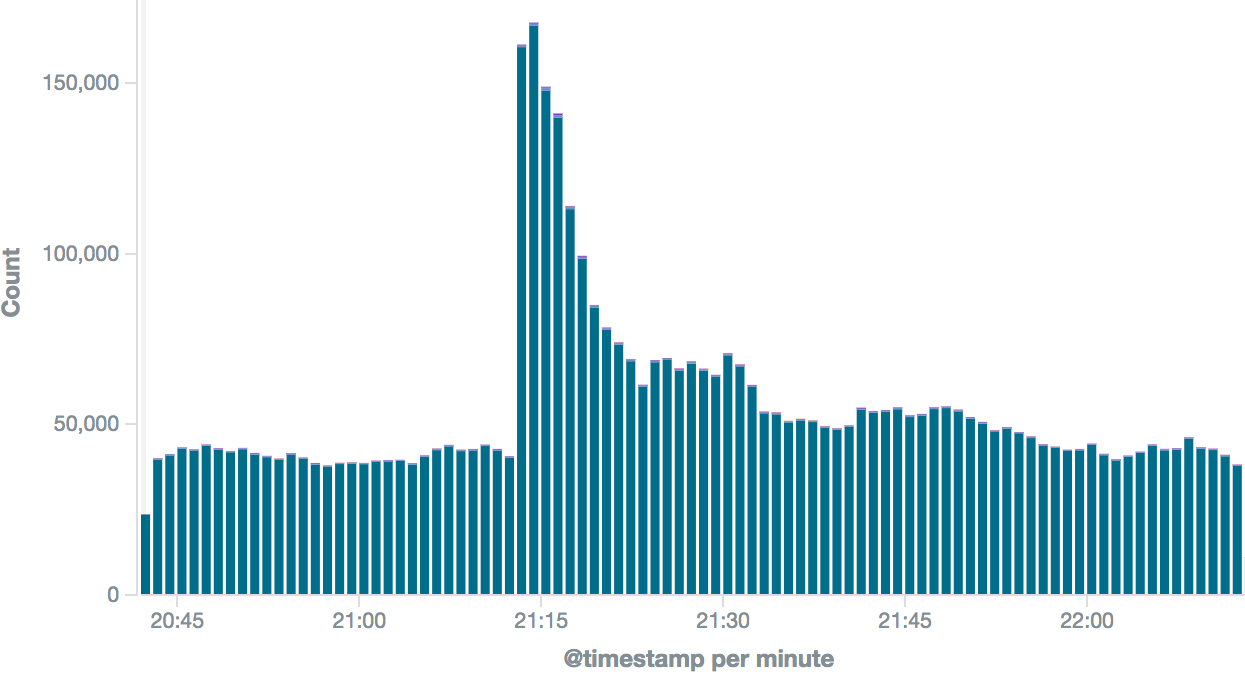
Typical traffic following breaking news push. Note: Not this actual event.
Tech stack anno 2014
Mid 2014 we had an API stack, based on Python and Django, that was providing data to the mobile apps. Furthermore, we had a stack delivering the website, based on PHP3. We were in the process of building a brand new, responsive website on top of API that was already used by the mobile app4.
Everything was running on co-located hardware in two datacenters. No Cloud. No CDN. No horizontal or vertical scaling options.
Caching was the game, and we had become quite good at that. At the edge we used Varnish, an amazing product with stellar performance5. Within applications, we used memcache in the old PHP parts, and Redis in the Python applications. Because of the various layers of cache, even during traffic bursts, the underlying MySQL database saw hardly any traffic increase and was not a component to worry about.
Video and images were handled by the ‘mediatool’ service, hosted in the same datacenters, having a similar setup: Varnish taking the brunt of the traffic impact.
A schematic view of our setup:

NU.nl tech stack anno 2014
Traffic hitting one of our systems could result in the following caching scenarios:
- Cache hit by Varnish: Extremely fast, very few system resources used
- Cache miss by varnish, pre-generated HTML on desktop site: Quite fast, some system resources used
- Cache miss by, dynamically generated content: Not so fast, most resource intensive
Metrics to check
At moments where the amount of traffic is extraordinarily high, there were some metrics to check:
Varnish
- Cache hit ratio - Needs to be high, a drop in this metric will cause extra load on the web servers
- Cache evictions - Varnish memory usage does not change, it remains constant. When memory is full, Varnish will evict items from cache following LRU. This will affect the cache hit ratio as well.
- CPU - This is proportional to traffic
- Bandwidth - We just can send so many bytes
- Backend connection errors - More requests going to the web servers than they can handle
Web servers
- CPU & Memory - The usual. If they get near the maximum capacity, there will be problems.
- APM - I’m not 100% sure, but I believe we already had New Relic APM back then, at least for the Python applications. New Relic APM proved to be a great way to quickly pinpoint problems with upstream APIs, or systems like MySQL and Redis.
External services
- Communication lines - We didn’t have direct visibility on metrics of services not managed by us. But could be easily contacted by the teams managing those services.
Datacenter
- NetScaler load balancer bandwidth - Very rare, but similar to individual servers: There is only so much they can stomach.
Knobs to dial
We had a number of tricks in our bag, to reduce load at various points in our stack:
Increase TTL
Almost all pages and API endpoints had a cache control setting of max-age=60. This mostly affected the volume of requests from Varnish to the backends: The web servers. To a lesser extent, it also decreased the volume of requests towards Varnish, depending on how browsers and API clients obeyed the cache-control directives.
Good for:
- Reducing traffic to web servers: Reduce CPU & Memory on web servers
- Reducing traffic towards Varnish: CPU & bandwidth varnish
Bad for:
- Time taken for editor changes in articles becoming visible to the end users. Not a good thing for a news site, so a trade-off considered carefully.
Throttle pre-generator processes
On the site web servers, several long-running processes existed that regularly pre-generated certain pages and fragments. Basically a request like any other, but instead of sending it back to the browser, the output was stored in a file. Similar to increasing the TTL of responses, the frequency of these jobs could be reduced.
Good for:
- Reducing background job CPU load on web servers, leaving more resources to handle actual requests.
Bad for:
- Time taken for updates to appear
Disable videos or advertisements
Toggles existed to turn off video on the entire site, or advertisements for individual articles or the entire site.
Removing adds was not about performance, but about removing the risk of inappropriate adds. Banner systems are automated, so there would be the risk of displaying last-minute holiday flight deals, while the entire site was showing content about the MH17 crash.
Good for:
- Reducing bandwidth needed by media service
- Reduce bandwidth at NetScaler
Bad for:
- Not showing the content we intend to show. Once again, a trade-off needing careful consideration.
An evening of monitoring
Around the time I arrived at home, another push message was sent:
18:20 - At least 20 Dutch people on board the crashed plane, follow our live blog here
By this time all news outlets were reporting on the crashed plane. At the start of the evening, a lot of people were commuting, either by car or public transport. So, almost everybody in the Netherlands would have been notified of the developing news, either by hearing about it on the radio or reading it on mobile devices. News travels, so with a bit of delay, traffic to the desktop website increased as well.
As a result, and of course because this particular news could have a very direct effect on a lot of Dutch people, traffic on our systems was at an all-time high.
Dinner was a hasty affair, and the evening consisted mostly of keeping an eye out on various metrics, and staying in touch with our team and other teams. Quite soon, another push message was sent, this time about a different news item:
19:42 - Israeli army begins ground offensive in Gaza Strip
Apparently, the world had gone mad. Compared to the direct impact the MH17 news had on the Netherlands, this news had a relatively small impact on traffic. About an hour later, another push message followed:
20:48 - 154 Dutch people in crashed plane in Ukraine
The entire evening, our systems received an enormous amount of traffic. Systems were holding up, but throughout the stack, things were at ‘orange levels’ of maximum capacity: The twilight zone of everything working fine, but not so fine as to being able to leave systems unattended. So we kept monitoring things, continuously discussing if we would need to take any action.
Ultimately, I can’t remember if we actually changed any of the configurations. We might have tuned the TTL values here and there. I know the option of disabling videos was discussed at some point. Although I’m not sure if we actually did that, it illustrates the unusual amount of traffic we were seeing that evening.
At the end of the evening, around midnight, things settled down. These types of ‘all hands on deck’ evenings require a bit of time to unwind, so it was a relatively short night of sleep.
Aftermath
The thing I remember most is that the actual news, only started to sink in the next morning. The evening itself had been all about checking systems and constantly evaluating trade-offs of possible mitigations, all at heightened levels of adrenaline.
We actually didn’t need to do a lot that evening. From that perspective, we have seen way worse. To me, it has been the evening of most intensively following the news ever, without actually following the news.
The Netherlands was in shock. My daily commute included Schiphol, and visiting the sea of flowers there, in the days following the crash, left a lasting impression.
It is an impressive day to remember. Even more so when realizing that 10 years later, Ukraine and Gaza are still the theater of horrible news events.

Sea of flowers at Schiphol airport in the days following the MH17 crash
-
It’s long ago. If not NetScaler, then Juniper. ↩︎
-
One might think it’s the impactful news items that have the highest open rate, but actually the more gossipy articles tend to rank the highest. ↩︎
-
The website stack was, at a high level, still similar to the one described in a talk “Surviving a Plane Crash” at the Dutch PHP Conference in 2009. A different plane crash by the way. ↩︎
-
That would be that ‘cache miss’ incident. ↩︎
-
Varnish is so good, Fastly built it’s CDN on top of it. ↩︎